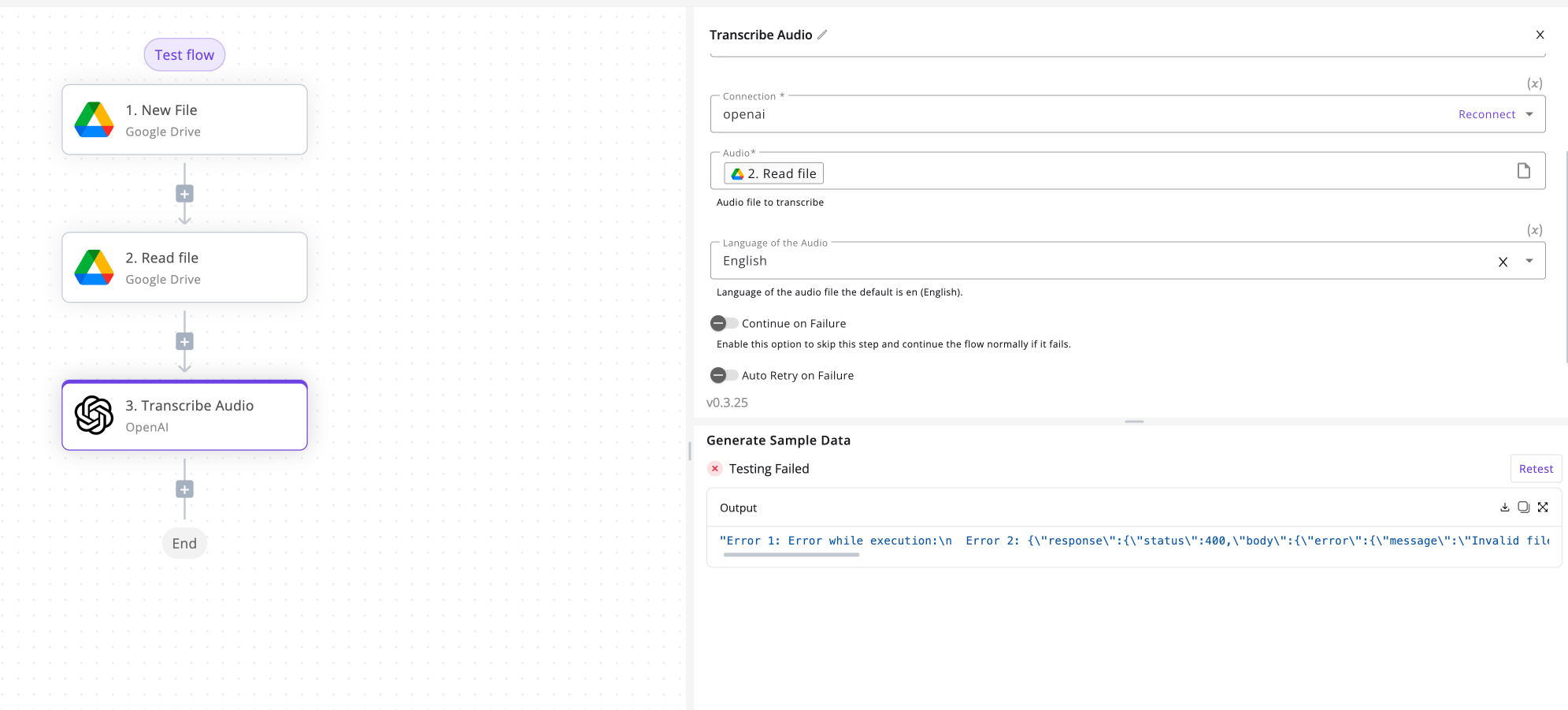
When I read a file from Google Drive and pass it to Whisper, it attaches an extension .mpga instead of the original audio extension (mp3, m4a). So Openai gives an invalid file type error.
I too am having this issue. I have a mp3 file and testing with Activepieces turns it into a mpga file. I would like to know why!
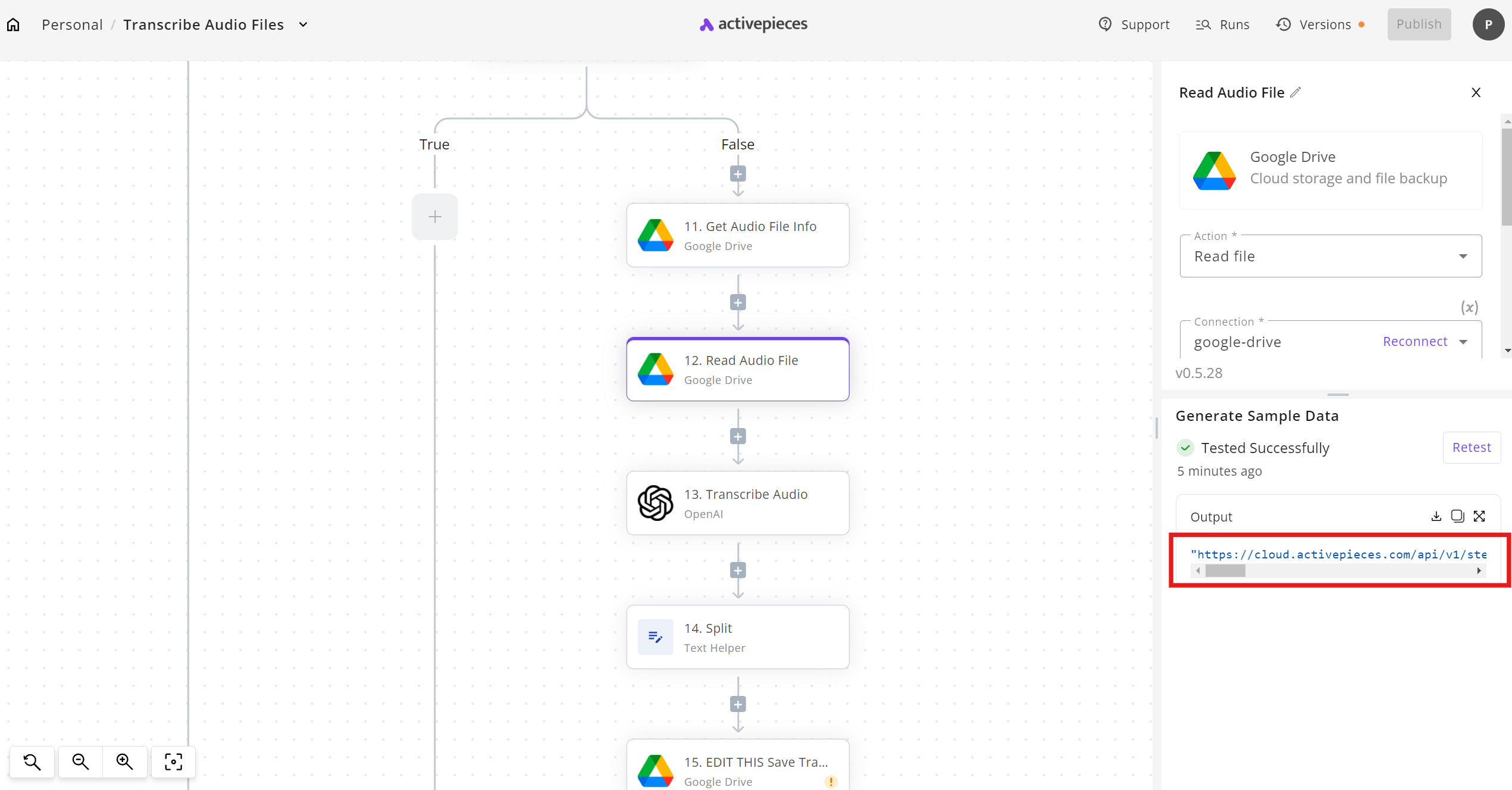
When I manually download the file using the link in the Google Drive Read file piece, it’s a .mpga file. How strange, then, that my OpenAI Transcribe Audio piece complains that the file format is unsupported since it lists mpga as a supported format!
The problem with not being able to test this step is that Activepieces blocks me from completing my final Google Drive piece to create a new text file because I did not successfully run the OpenAI Transcribe Audio piece and don’t have its output to use.
Would really appreciate any help or workarounds. I’ve been unable to complete a single one of my Activepieces flows because of one issue or another like this.
If the Transcribe Audio piece is, say, step_2 then you can bypass having to get test data from it first by using what seems to me to be a mustache template. In this example, I got the text element of the output with the notation: {{step_2.text}}