Hi all,
Tried searching the community, but didn’t find anything.
What is the best way of parsing / reading a PDFs content received? (either via a form, or email, or anything else)
Hi all,
Tried searching the community, but didn’t find anything.
What is the best way of parsing / reading a PDFs content received? (either via a form, or email, or anything else)
autokent / pdf-parse · GitLab is one of the best options we have available.
You can also use external APIs to parse PDF files like
Thanks, but I’m not that technical so this wouldn’t work unfortunately. Is there another workflow around it?
Sure, I can spend some time write a flow to extract text from PDF files.
But the flow might* change depending on how you get the PDF file, It will be different if you specify the PDF URL, different if we have access to an actual PDF (file blob).
Whatever you’re trying to do, do you have access to the PDF file URL or an actual PDF file? or both?
This would be something great! Looking for a solution too I will need to run several PDF’s every day. Would you be able to capture markup too?
Do you have any sample PDF with markups? (can you upload and share it?)
PS: I assume by markup you mean annotations!
Sure here you go,
Yeah like headers and bold text and stuff, not sure if you can scraper that from a PDF would be amazing though!
No that’s not possible, should be possible with paid APIs or one might have to create their own PDF parser for this.
A far fetched possibility is to to convert each page in PDF to an image, use image LLMs to process the image and extract everything - that includes headers, bold texts. tables, etc.
Yes I was expecting that too, do you know any paid APIs?
Also ie as thinking if you could splitscrape every title and body below it, I would be able to give the annotation later but you would need to have them all. Nu sure if that is possible
Title1
Body 1
Title 2
Body 2
Etc
Then make the title bold or give it a header. Maybe even based on 1, 1.1, 1.1.1, or so. Nu sure what the possibilities are
I think for this specific use case you need to research more and find the perfect API, You can look at the links I had shared previously.
This seems like the perfect solution https://developer.adobe.com/document-services/docs/overview/pdf-extract-api/howtos/extract-api/ for you, If Adobe can’t handle it, nobody can.
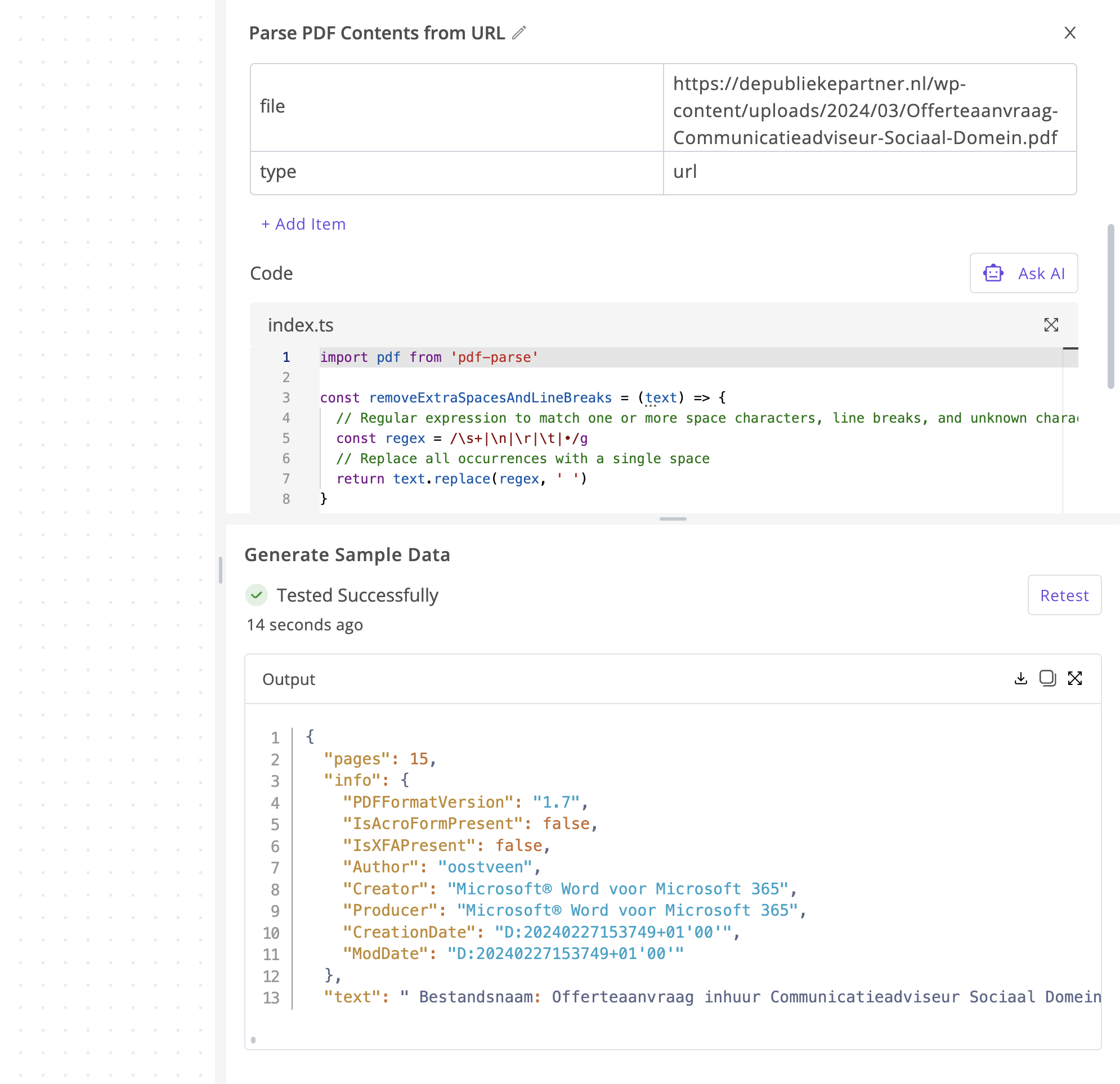
@karla @Bram To extract text from PDF file (either url or base64 of file)
import pdf from 'pdf-parse'
const removeExtraSpacesAndLineBreaks = (text) => {
// Regular expression to match one or more space characters, line breaks, and unknown characters
const regex = /\s+|\n|\r|\t|•/g
// Replace all occurrences with a single space
return text.replace(regex, ' ')
}
export const code = async (inputs) => {
const file = inputs.type === 'url' ? inputs.file : "data:application/pdf;base64," + inputs.file
const res = await fetch(file)
const buffer = await res.arrayBuffer()
const pages = await pdf(buffer)
// console.log('pages', pages)
let text = pages.text
// optional - remove all extra spaces and new lines from the text
// if you don't need this, comment the line below!
text = removeExtraSpacesAndLineBreaks(text)
return {
pages: pages.numpages,
info: pages.info,
text,
}
};
Expand the code block and click on “Add npm package” , enter “pdf-parse” as the package name and click on add
In the code block, add these variables file and type
file: File can be either be a url to the pdf or base64 of the file
type: It should either be url or base64 (depending on what you have entered in the file input)
Hope it helps.
Thanks!! This is what I am after. They have a free monthly 500 document transactions. I’ll try to give it a go today and let you know the outcome. I also requested for a quote to know the pricing afterwards.
Awesome work @IOBLR ! thank you so much from all of us who use PDFs! I have used Tesseract OCR since I think it’s the most accurate open source OCR tool (from Google too, IIRC). Maybe that can be of use instead of trying to process images with an LLM. Once we have the OCR output we can select all the text and potentially choose to copy With Formatting or Without. I didn’t review your code but will wait @Bram to say how it worked on his side ? ![]()
Sorry for the delay, was stuck in other priorities. Will give it a go as soon as I can and let you know the outcome
Sooooo… I found some time but no luck on Adobe yet… I did find the demo which shows the results, which look very promosing Extract Text from PDF | Extract Data from PDF | Visualizer - Adobe Developers
I find it very difficult to understand their API Reference as it seems that I am not allowed to use an external source for the extra PDF, https://developer.adobe.com/document-services/docs/overview/pdf-services-api/howtos/pdf-external-storage-sol/
Which is oke because I then look for a workaround, SO i am looking for a way to upload a PDF to the internal Adobe Cloud Storage… no documentation to be found…
So back at the API Reference from where it all began… https://developer.adobe.com/document-services/docs/apis/#tag/Extract-PDF here was my starting point.
@IOBLR @Pierce_Mooney If one of might want to take a look? i have credentials available for testing, please DM me is you need them.
KR Bram
Again some create work @IOBLR this really helps getting the text from the PDF! this will help a lot of people and easy to install thanks for the simple steps you created for us!
I looked at their API Example here https://developer.adobe.com/document-services/docs/overview/pdf-extract-api/howtos/extract-api/ & https://github.com/adobe/pdfservices-node-sdk-samples/blob/master/src/extractpdf/extract-text-info-from-pdf.js
You can easily pass in your own PDF file and extract the contents out of it, I don’t see any limitations.
Checkout this line https://github.com/adobe/pdfservices-node-sdk-samples/blob/fce2f664e5e435cea4954ccc1b7107993d91a660/src/extractpdf/extract-text-info-from-pdf.js#L35 you can clearly see we can specify the file locally and technically it would work.
Did you try their npm package/node example?
As for their REST API, even I wasn’t able to find how to upload an actual document, I will dig deeper and update my findings here.
Also, I wasn’t able to find the pricing for their services @Bram If you have info on their pricing can you share that?
Hi Druhv,
Thanks for taking a look! It might be easy for you but my technical/coding knowledge is very limited. But happy to hear it’s not complicated to use. I havent tried their NPM package, not really sure how I should…
Regarding their pricing you have 500 free credits every month, above that you should contact Sales, I did but no reply. Requested for a price for 1500 a month but I think that might be to low numbers for them.
I hope this weekend I have time for further testing otherwise next week somewhere I assume.
Kr Bram
Makes sense - sorry for making assumptions.
Can you DM me your credentials? client_id and client_secret?
Reference Links: