Hi @abuaboud
Yeah now the VAR description is much clearer…
The reason why I’m trying to move off from N8N, is because to me they lost the “open-source” vibe they had, and they now focus exclusively on non self-hosted users… they release very buggy versions, and it’s a pain to install npm packages as it requires to re-deploy everything, the executions history can’t be externalized for example to Axiom or any sentry logger if you don’t get an Enterprise version (15k euro)… etc… (ActivePieces doesn’t offer externalization of execution history either, but I hope someday that feature will be available for everyone and not only for paid customers)
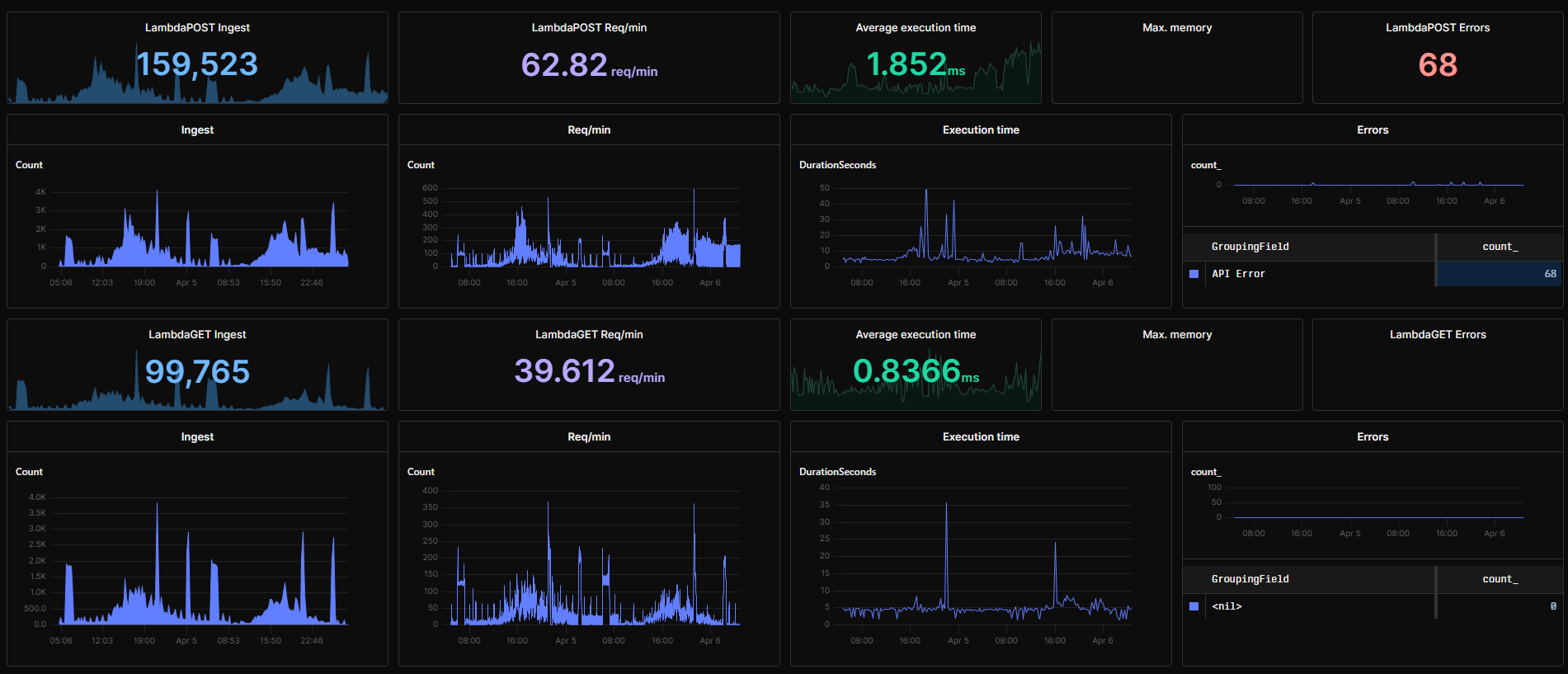
In general, I found N8N pretty buggy in the last year, so I am looking for some solid alternatives to that… My current N8N instance processes about 50k/req/day with a main instance + 10 workers…
There is a lot of stuff that I love from ActivePieces, for example, the clean UI—it’s much better. The code node—it’s much better. It’s super easy to add NPM packages, and the interface is very solid. In my opinion, there are some options that should be available in the hosted solution and not paid features, but…
I mean, the target for paid users that use ActivePieces is users that want to automate their stuff but don’t want to struggle with hosting it. I’m more than happy that ActivePieces or any other tool like N8N makes paid features, ok, but don’t make “key features” like GIT sync or logging behind a paywall… Make company stuff as paid, like inviting multiple users, roles, white-labeling, etc…
Back to workers, main, etc., I think N8N has defined that a lot better than ActivePieces, where each instance does just one thing. Usually when you have polyvalent instances, they have a poor performance in everything; that’s why I like it much more to have:
- Webhook instance or instances (when more than one, connected through a balancer): ONLY receive API requests and add the TASKS to the REDIS queue.
- Workers: ONLY process tasks AVAILABLE in the REDIS queue.
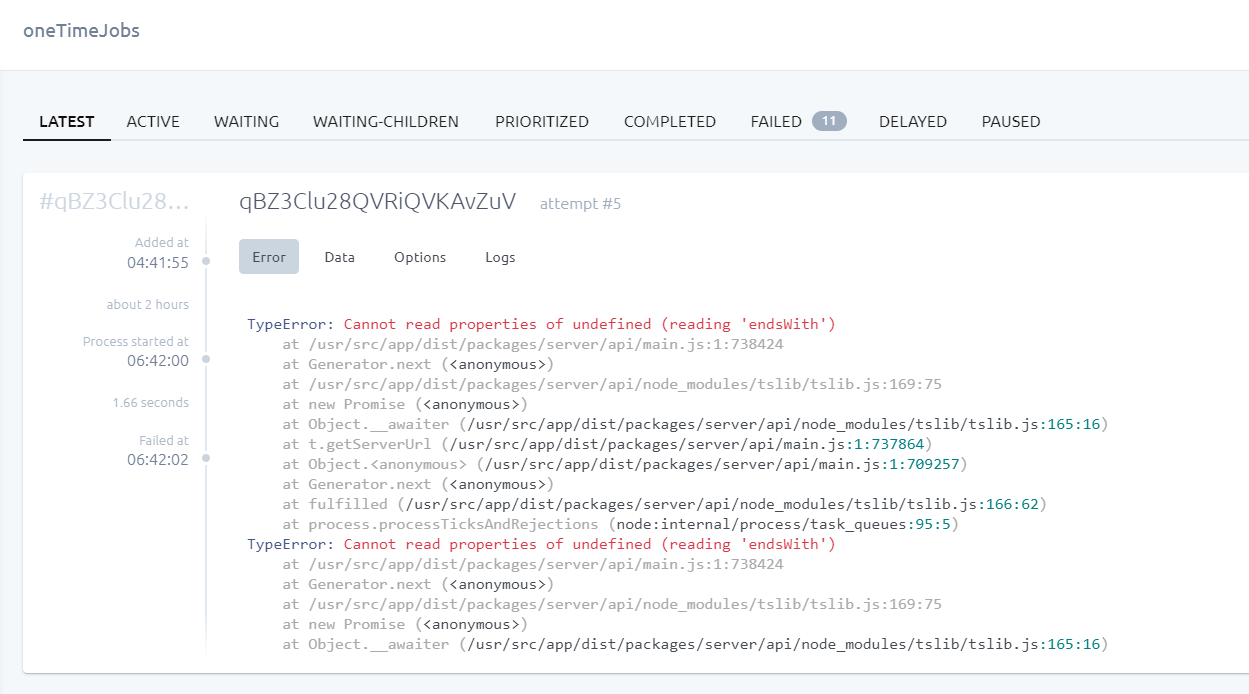
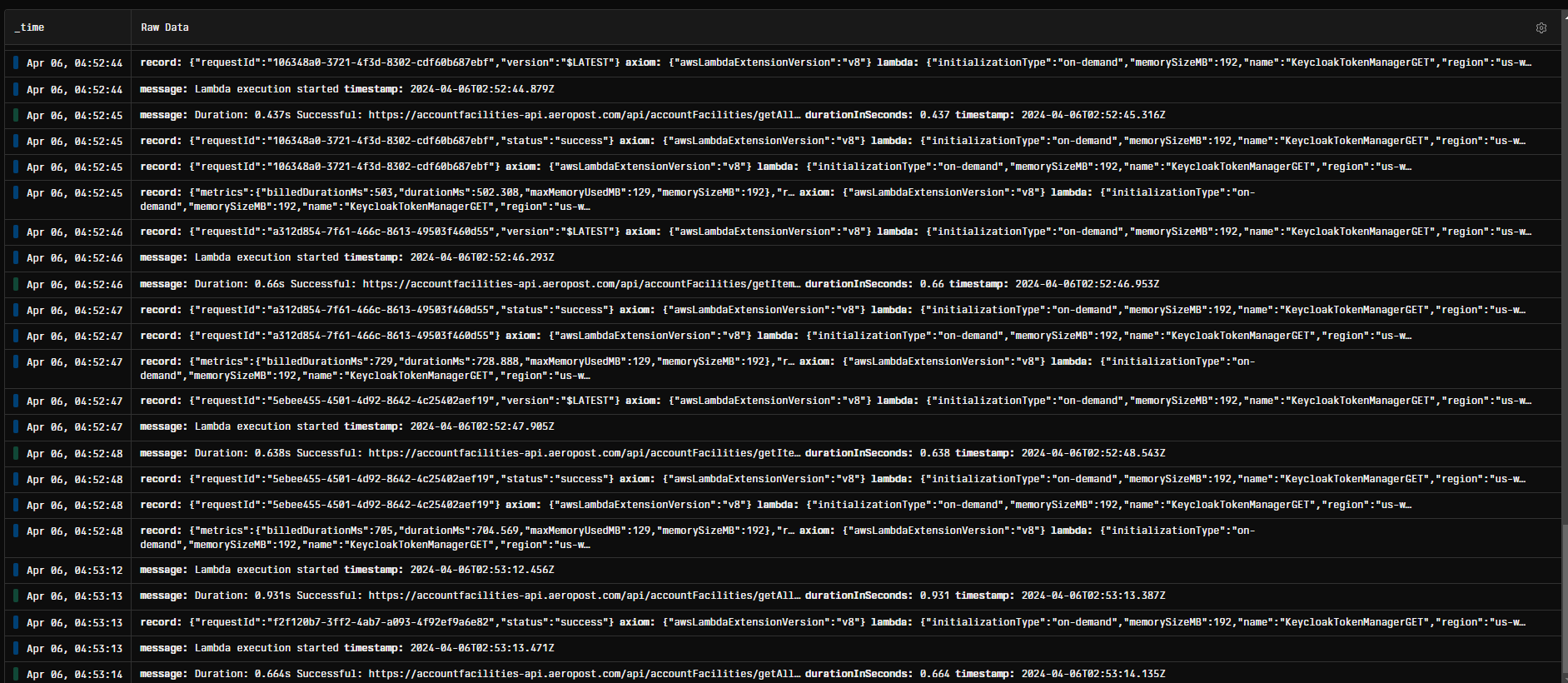
There is still a lot that I need to learn from ActivePieces, but overall, I like the tool. But to me, right now, it feels too slow when I send a bulk of 100 API requests in 1 second it takes a few minutes to react…
As soon as the tasks are added to the queue, the workers finish them quickly, the issue is the time since the request is sent to ActivePieces, until Workers start to process the requests…
Happy to share the logs if you want…