@MoShizzle @abuaboud @ashrafsam - folks, SOS, I have workflows fail due to connections failing to load.
Here’s Airtable:
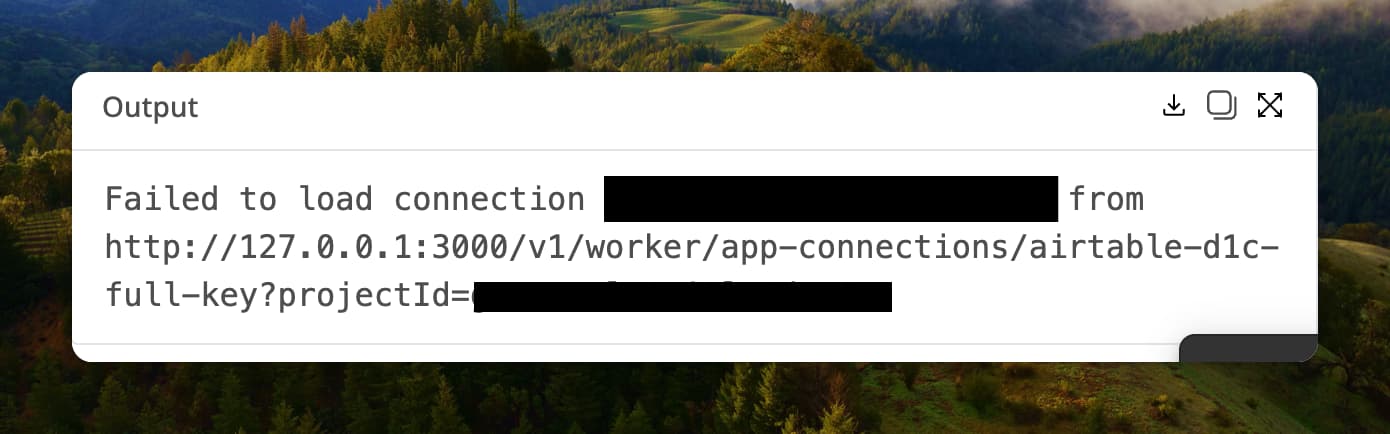
Run: TYtTNi2wSGAvEG480PRgy
Here is Drip:

Run: PifeW4Bw2BUH9dooSDFKw.
Needs fixing ASAP please.
@MoShizzle @abuaboud @ashrafsam - folks, SOS, I have workflows fail due to connections failing to load.
Here’s Airtable:
Run: TYtTNi2wSGAvEG480PRgy
Here is Drip:
Run: PifeW4Bw2BUH9dooSDFKw.
Needs fixing ASAP please.
On it, sorry about this @Evgeny
Hi @Evgeny
I am taking look right now
My current investigation seems it effects couple of runs, seems there is a network failure happens from time to time to certain small set of runs , I will find the root cause but in mean time I will try to push a triage too
They have been retried and run should turn into success, the error disappeared and add more information so we can catch the root if it come back
I am going to work on added these cases to be marked as internal errors, the internal errors get direct into retries queue and notify our team.
Thank you for the prompt actions.
@abuaboud - just had another fail. Also drip. Same error.
Run 7H77vJi6M41eSMRNCmpRv.
Flow:
Error: Failed to load connection (drip) from http://127.0.0.1:3000/v1/worker/app-connections/drip?projectId=guz7nTclsGoi8ln6dsX6L error: {“cause”:{“errno”:-111,“code”:“ECONNREFUSED”,“syscall”:“connect”,“address”:“127.0.0.1”,“port”:3000}}
Hi @Evgeny,
Sorry for that. The team has already been notified and the run has been fixed this morning.
We are still trying to figure out where it’s coming from. Today, as I mentioned, we will implement a system where these errors will be marked as internal errors for retries, It should be done around end of today.
It usually happens after deployment to at most one random worker. The exact issue is not known and the error is well known but the reason is not known on most of issues we read over internet, but we will upgrade the underlying infrastructure and continue monitoring, the feature we will release today will automatically fix these issues without user intervention but the root reason is still unknown.
Folks, you really need to track this one down.
Re: random - for some reason, this is not the first time Drip failed.
I’ll keep reporting.
@Evgeny, Great thank you!
We are almost done with the fix. After we land it, you should no longer see this error, because it will be detected by engine and deal with it gracefully, without anyone intervention.
We did setup an graph to monitor this error in the previous couple of days until the team finish the fix.
@Evgeny Just wanted to confirm that safeguards are now implemented and deployed ![]()
Thank you!! Appreciate the effort to fix this for good.
This topic was automatically closed 24 hours after the last reply. New replies are no longer allowed.
Update: We found the root cause. It was due to certain machines taking a long time to connect to Redis, causing an error that corrupt the machine. Half of the modules were up and running, while the rest were not.
Now that this has been fixed, we increased the timeout and made the container exit if it failed to initialize.
